



I tweeted about reactivity, which got a lot of traction, so I decided to expand my thoughts here.

Innovations of different frameworks from my perspective.
@angular, React,
@sveltjs,
@solid_js,
@QwikDev
🧵
This post is not an authoritative history of reactivity but my personal journey and opinions on the subject.
I started my journey with Macromedia Flex, which later got purchased by Adobe. Flex was a framework on top of Flash in ActionScript. ActionScript is very similar to JavaScript, but it had annotations allowing the compiler to wrap fields for a subscription. I don't remember the exact syntax and can't find much on the web, but it looked something like this:
class MyComponent {
[Bindable] public var name: String;
}The [Bindable] annotation would create a getter/setter, which would fire events on property change. You could then listen to the property changes. Flex came with templating .mxml files to render UI. Any data bindings in .mxml were fine-grained reactive if the property changed by listening to the property changes.
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml">
<mx:MyComponent>
<mx:Label text="{name}"/></mx:Label>
</mx:MyComponent>
</mx:Applicatio>I doubt that Flex was the original place where reactivity first existed, but it was my first encounter with reactivity.
Reactivity was kind of a pain in Flex because it easily allowed creating update storms. An update storm is when a single property change triggers many other properties (or templates) to change, which triggers more properties to change, and so on. At times, this would get into infinite loops. Flex did not differentiate between updating a property and updating the UI, causing a lot of UI thrashing (rendering intermediary values).
With the benefit of hindsight, I can see which architectural decisions led to this suboptimal outcome, but at the time, that was not clear to me, and I walked away with a bit of distrust of reactive systems.
The original goal of AngularJS was to extend the HTML vocabulary so that designers (non-developers) could build simple web applications. This is the reason why AngularJS ended up with HTML markup. Because AngularJS extended HTML, it needed to bind to any JavaScript object. Neither Proxy, getter/ setters, nor Object.observe() were an option back then. So the only solution available was to do dirty checking.
Dirty checking works by reading all of the properties bound in the templates every time the browser performs any asynchronous work.
<!doctype html>
<html ng-app>
<head>
<script src="https://ajax.googleapis.com/ajax/libs/angularjs/1.8.2/angular.min.js"></script>
</head>
<body>
<div>
<label>Name:</label>
<input type="text" ng-model="yourName" placeholder="Enter a name here">
<hr>
<h1>Hello {{yourName}}!</h1>
</div>
</body>
</html>The nice thing about this approach is that any JavaScript object can be used as a data-binding source in the template, and the updates just work.
The downside is that a lot of JavaScript must execute each update. And because AngularJS does not know when a change may have accrued, it runs dirty-checking way more often than is theoretically necessary.
Because AngularJS just worked with any object and because it was meant as an extension to the HTML syntax, AngularJS never codified any sort of state management.
React came out after AngularJS (before Angular) and had several improvements.
First, React introduced setState(). This allowed React to know when it should do dirty-checking of the vDOM. The benefit of this is that unlike AngularJS, which ran dirty-checking on each async task, React only did it when the developer told it to. So even though React vDOM dirty-checking is more computationally expensive than AngularJS, it would run it less often.
function Counter() {
const [count, setCount] = useState();
return <button onClick={() => setCount(count+1)}>{count}</button>
} Second, React introduced strict data flow from parents to children. These were the first steps toward framework-sanctioned state management, which AngularJS did not have.
Both React and AngularJS are coarse-grain reactive. Meaning that a change in data would trigger a large amount of JavaScript to execute. The framework would eventually reconcile all of the changes into the UI. This meant that fast-changing properties such as animation would cause performance issues.
The solution to the above is fine-grained reactivity, where state changes only update the part of the UI to which the state is bound to.
The hard part is knowing how to listen to property changes in a way that has good DX.
Backbone predates AngularJS, and it had fine-grained reactivity, but the syntax was very verbose.
var MyModel = Backbone.Model.extend({
initialize: function() {
// Listen to changes on itself.
this.on('change:name', this.onAsdChange);
},
onNameChange: function(model, value) {
console.log('Model: Name was changed to:', value);
}
});
var myModel = new MyModel();
myModel.set('name', 'something');I think the verbose syntax is part of why frameworks like AngularJS and later React took over because developers could simply use the dot notation to access and set state instead of a complex set of function callbacks. Developing the applications in these newer frameworks was easier and quicker.
Knockout came about at the same time as AngularJS. I never used it, but my understanding is that it also suffered from the update storm issue. While it was an improvement on Backbone.js, working with observable properties was still clunky, which again is why I think that developers preferred the dot notation frameworks such as AngularJS and React.
But Knockout had an interesting innovation — computed properties, which might have existed before, but it is the first I’d heard of it. They would automatically create subscriptions on its inputs.
var ViewModel = function(first, last) {
this.firstName = ko.observable(first);
this.lastName = ko.observable(last);
this.fullName = ko.pureComputed(function() {
// Knockout tracks dependencies automatically.
// It knows that fullName depends on firstName and lastName,
// because these get called when evaluating fullName.
return this.firstName() + " " + this.lastName();
}, this);
};Notice that when ko.pureComputed() invokes this.firstName(), the invocation of the value would implicitly create a subscription. This is done by ko.pureComputed() setting a global variable that allows this.firstName() to communicate with ko.pureComputed() and pass the subscription information to it without any additional work for the developer.
Svelte incorporated reactivity using a compiler. The advantage here is that with a compiler, the syntax can be whatever you want. You are not constrained by JavaScript. Svelte has a very natural reactivity syntax for components. But Svelte does not compile all of your files, only the files ending with the .svelte extension. If you want reactivity in non-compiled files, Svelte provides a store API, which lacks the magic of compiled reactivity and requires more explicit registrations using subscribe and unsubscribe.
const count = writable(0);
const unsubscribe = count.subscribe(value => {
countValue = value;
});I think having two different ways of doing the same thing is not ideal, as you have to keep two different mental models in your head and choose between them. A single way of doing it would be preferred.
RxJS is a reactive library not tied to any underlying rendering system. That may seem like an advantage, but it has a downside. Navigating to a new page requires a teardown of the existing UI and the buildup of a new UI. For RxJS, this means that many unsubscribes and subscribes need to happen.
This extra work means that coarse-grained reactive systems are faster in this scenario because teardown is just throwing away the UI (garbage collection), and the buildup does not require any registration/allocation of listeners. What we need is a way to bulk unsubscribe/subscribe.
const observable1 = interval(400);
const observable2 = interval(300);
const subscription = observable1.subscribe(x => console.log('[first](https://rxjs.dev/api/index/function/first): ' + x));
const childSubscription = observable2.subscribe(x => console.log('second: ' + x));
subscription.add(childSubscription);
setTimeout(() => {
// Unsubscribes BOTH subscription and childSubscription
subscription.unsubscribe();
}, 1000);Around the same time, both Vue and MobX started experimenting with proxy-based reactivity. The advantage of proxies is that you can have clean dot notation syntax, which the developers prefer, and you can use the same tricks as Knockout to create automatic subscriptions — a huge win!
<template>
<button @click="count = count + 1">{{ count }}</button>
</template>
<script setup>
import { ref } from "vue";
const count = ref(1);
</script>In the example above, the template automatically creates a subscription to the count by reading the count value during render. No additional work is required on the part of the developer.
The downside of Proxies is that one can't pass a reference to the getter/setters. You either pass the whole proxy or the value of a property, but you can peel off a getter from the store and pass that. Take this problem as an example.
function App() {
const state = createStateProxy({count: 1});
return (
<>
<button onClick={() => state.count++}>+1</button>\
<Wrapper value={state.count}/>
</>
);
}
function Wrapper(props) {
return <Display value={state.value}/>
}
function Display(props) {
return <span>Count: {props.value}</span>
}When we read state.count, the resulting number is primitive and no longer observable. This means both Middle and Child need to re-render on the state.count change. We lost fine-grained reactivity. Ideally, only the Count: should be updated. What we need is a way to pass a reference to the value rather than the value itself.
A signal allows you to refer not just to the value but also to the getter/setter of that value. So you can solve the above with signals:
function App() {
const [count, setCount] = createSignal(1);
return (
<>
<button onClick={() => setCount(count() + 1)}>+1</button>
<Wrapper value={count}/>
</>
);
}
function Wrapper(props: {value: Accessor<number>}) {
return <Display value={props.value}/>
}
function Display(props: {value: Accessor<number>}) {
return <span>Count: {props.value}</span>
}The nice part of this solution is that we are not passing the value but rather an Accessor (a getter). This means that when the value of the count changes, we don't have to go through Wrapper and Display. We can go directly to the DOM for an update. It is very similar to Knockout in how it works but similar to Vue/MobX in syntax.
But this has a DX problem. As a user of a component, let's say we would like to bind to a constant:
<Display value={10}/>This will not work because Display is defined as Accessor:
function Display(props: {value: Accessor<number>});This is unfortunate because the author of the component now defines if the consumer can send a getter or a value. Whatever the author chooses, there will always be a use case not covered. Both of these are reasonable things to do.
<Display value={10}/>
<Display value={createSignal(10)}/>The above are two valid ways to use Display, but they both can't be true! What we need is a way to declare the types as primitives but have it work both with primitives and with Accessors. Enter the compiler.
function App() {
const [count, setCount] = createSignal(1);
return (
<>
<button onClick={() => setCount(count() + 1)}>+1</button>
<Wrapper value={count()}/>
</>
);
}
function Wrapper(props: {value: number}) {
return <Display value={props.value}/>
}
function Display(props: {value: number}) {
return <span>Count: {props.value}</span>
}Notice that now we declare number, not Accessor. This means that this code will work just fine.
<Display value={10}/>
<Display value={createSignal(10)()}/> // Notice the extra ()But does it mean that we have now broken the reactivity? The answer would be yes, except we can have a compiler perform a trick to restore our reactivity. The problem is this line:
<Wrapper value={count()}/>Invocation of count() turns the Accessor into a primitive value and creates a subscription. So the compiler does this trick.
Wrapper({
get value() { return count(); }
})By wrapping the count() in a getter when passing it to a child component as a property, the compiler has managed to delay the execution of count() long enough until it is actually needed for the DOM. This allows the DOM to create a subscription on the underlying signal even though, to a developer, it seems like a value was passed.
Benefits are:
- Clean syntax
- Automatic subscriptions and unsubscriptions
- The component interface does not have to choose between primitive and
Accessor. - The reactivity works even if the developer converts the
Accessorto a primitive.
What can we possibly improve on this?
Let's imagine this situation with a product page with a buy button and a shopping cart.
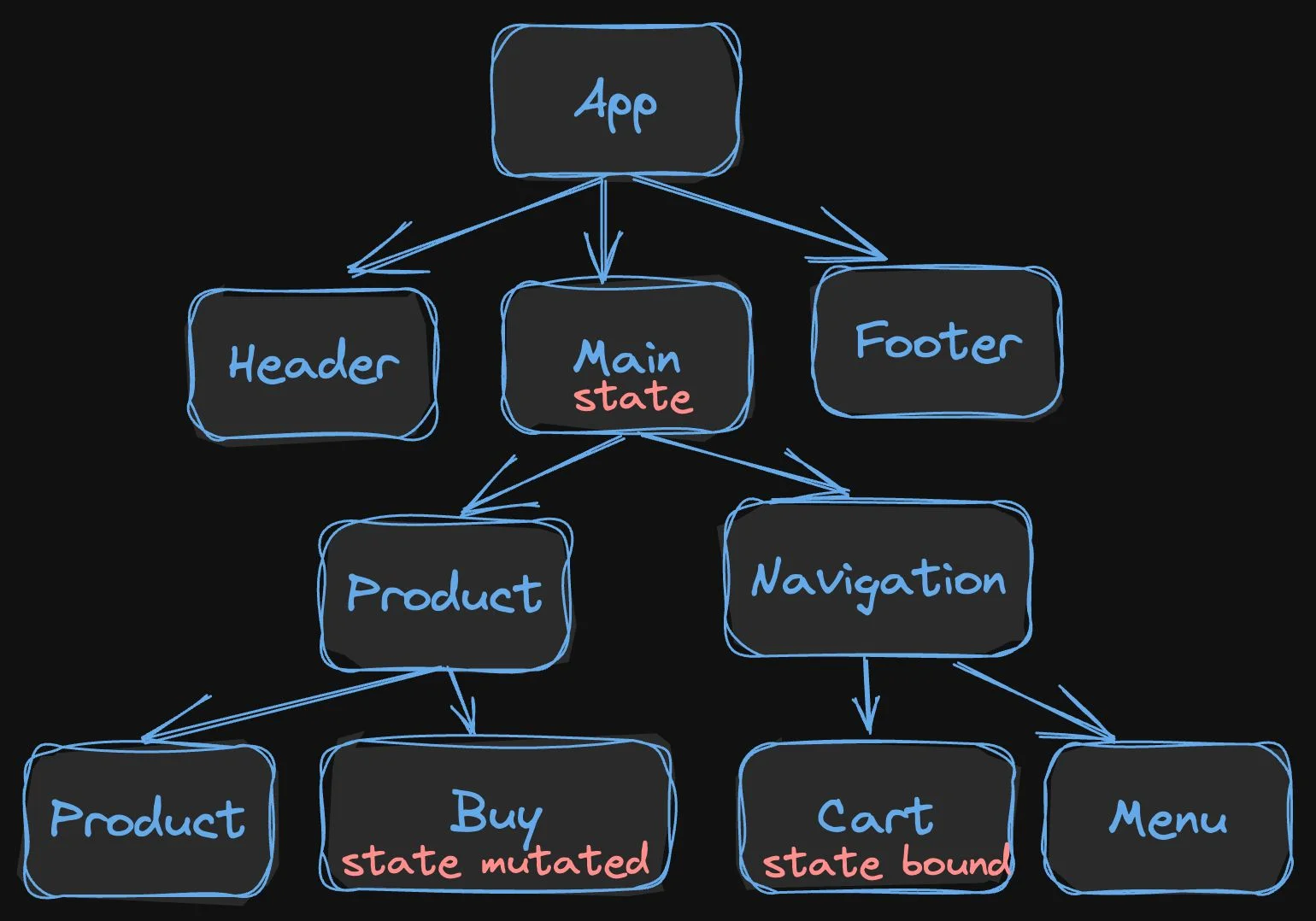
In the example above, we have a collection of components in a tree. A possible action a user may take is to click on the buy button, which needs to update the shopping cart. There are two different kinds of outcomes as to what code needs to execute.
In a coarse-grained reactive system, it is like this:
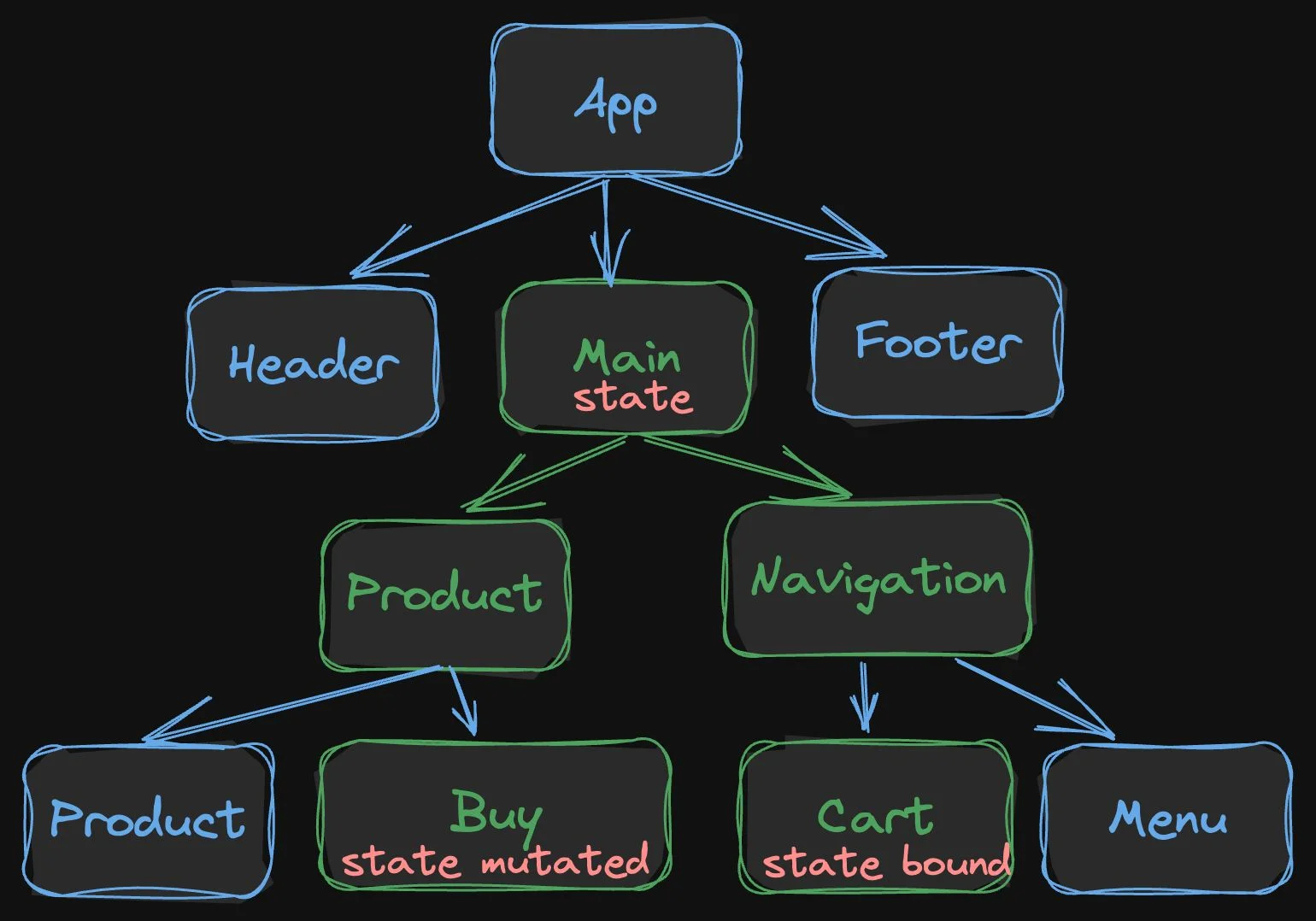
We must find the common root between the Buy and Cart components, as that is where the state is most likely attached. Then, upon changing the state, the tree associated with that state must re-render. Using memoization, it is possible to prune the tree into just the two minimal paths, as shown above. A lot of code still needs to be executed, especially as the application gets more complex.
In a fine-grained reactive system, it looks like this:
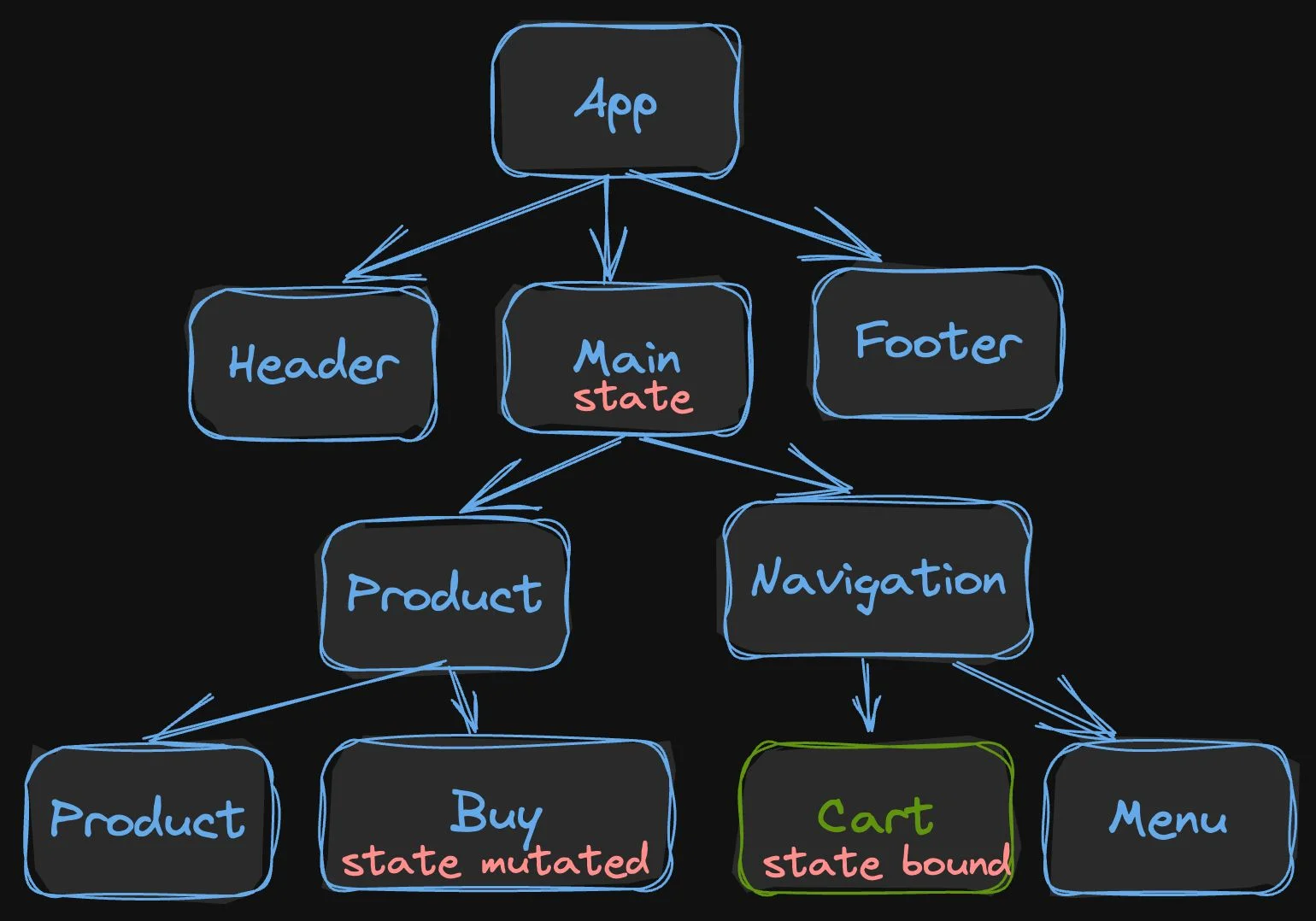
Notice that only the destination, Cart, needs to execute. No need to look where the state was declared or what the common ancestor is. It is also unnecessary to worry about data memoization to prune the tree. The nice part of fine-grained reactive systems is that without any effort on the part of the developer, a minimal amount of code executes at runtime!
The surgical precision of fine-grained reactive systems makes them ideal for lazy execution of the code because the system only needs to execute the listener of the state (in our case, the Cart).
But fine-grained reactive systems have an unexpected corner case. For the system to build up the reactivity graph at least once, the reactivity system must execute all of the components to learn about the relationships! Once built up, the system can be surgical. This is what the initial execution looks like:
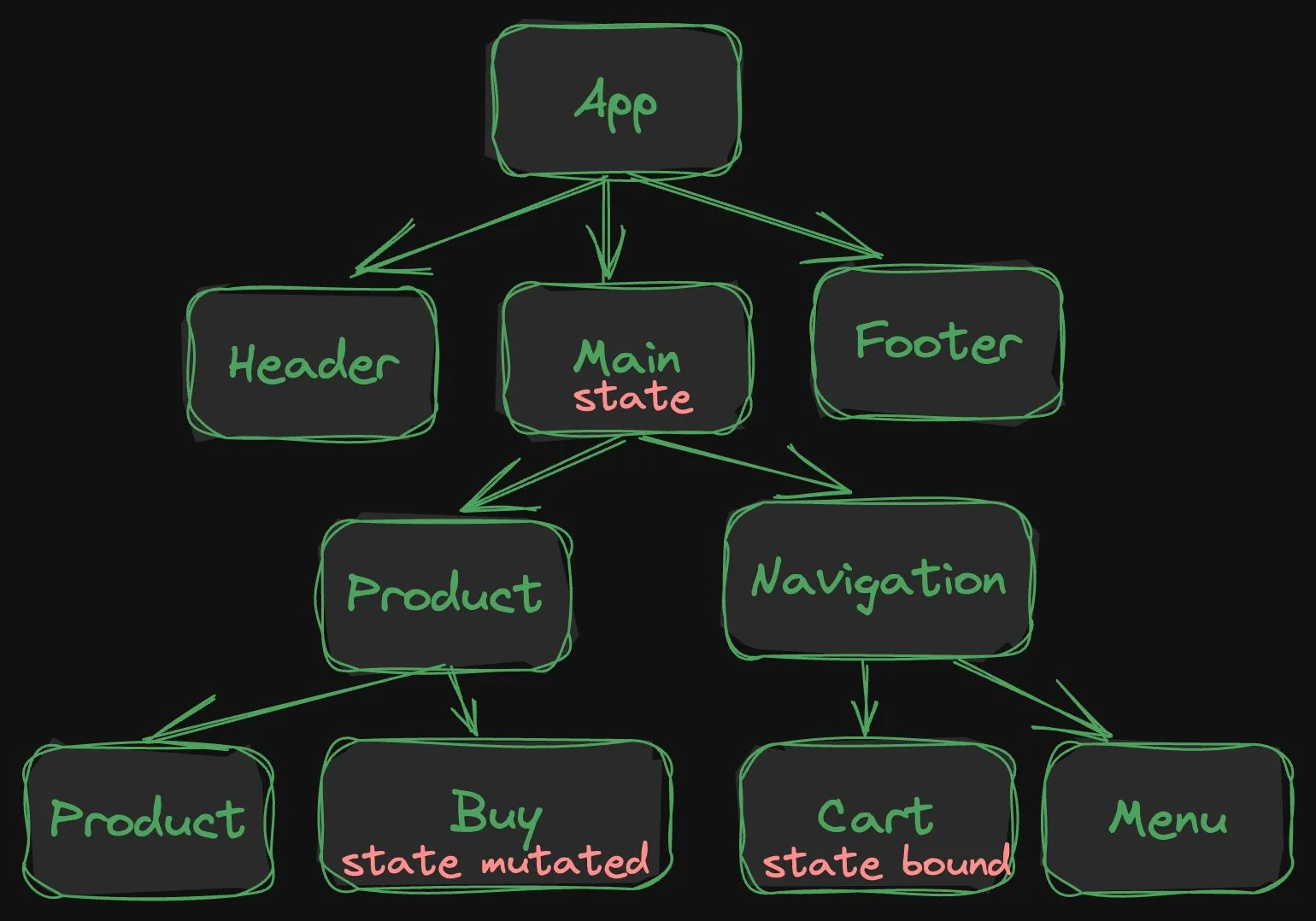
See the problem? We want to be lazy about download and execution, but the initialization of the reactive graph forces full execution (download) of the application.
This is where Qwik comes in. Qwik is fine-grained reactive, similar to SolidJS, meaning that a change in the state directly updates the DOM. (In some corner cases, Qwik may need to execute the whole component.) But Qwik has a trick up its sleeve. Remember that fine-grained reactivity requires that all components execute at least once to create the reactivity graph?
Well, Qwik takes advantage of the fact that the components have already been executed at the server during SSR/SSG. Qwik can serialize this graph into HTML. This allows the client to entirely skip the initial "execute the world to learn about the reactivity graph". We call this resumability. Because components do not execute, or download, on the client, Qwik’s benefit is the instant startup of the application. Once the application is running, the reactivity is surgical, just like that of SolidJS.
As an industry, we have gone through many iterations of reactivity. We started with coarse-grain reactive systems because they were friendlier toward developers. But we have always retained sight of the value of having fine-grain reactive systems and have been chipping away at this problem for a while.
The latest generation of frameworks have solved many issues around the developer experience, update storms, and state management. I don't know which framework you will choose next, but I bet it will be fine-grained reactive!
Builder.io visually edits code, uses your design system, and sends pull requests.
Builder.io visually edits code, uses your design system, and sends pull requests.
 Connect a Repo
Connect a Repo











