


There has been a lot of talk about resumability, so let’s build a resumable web application from the ground up to explain the concept better.
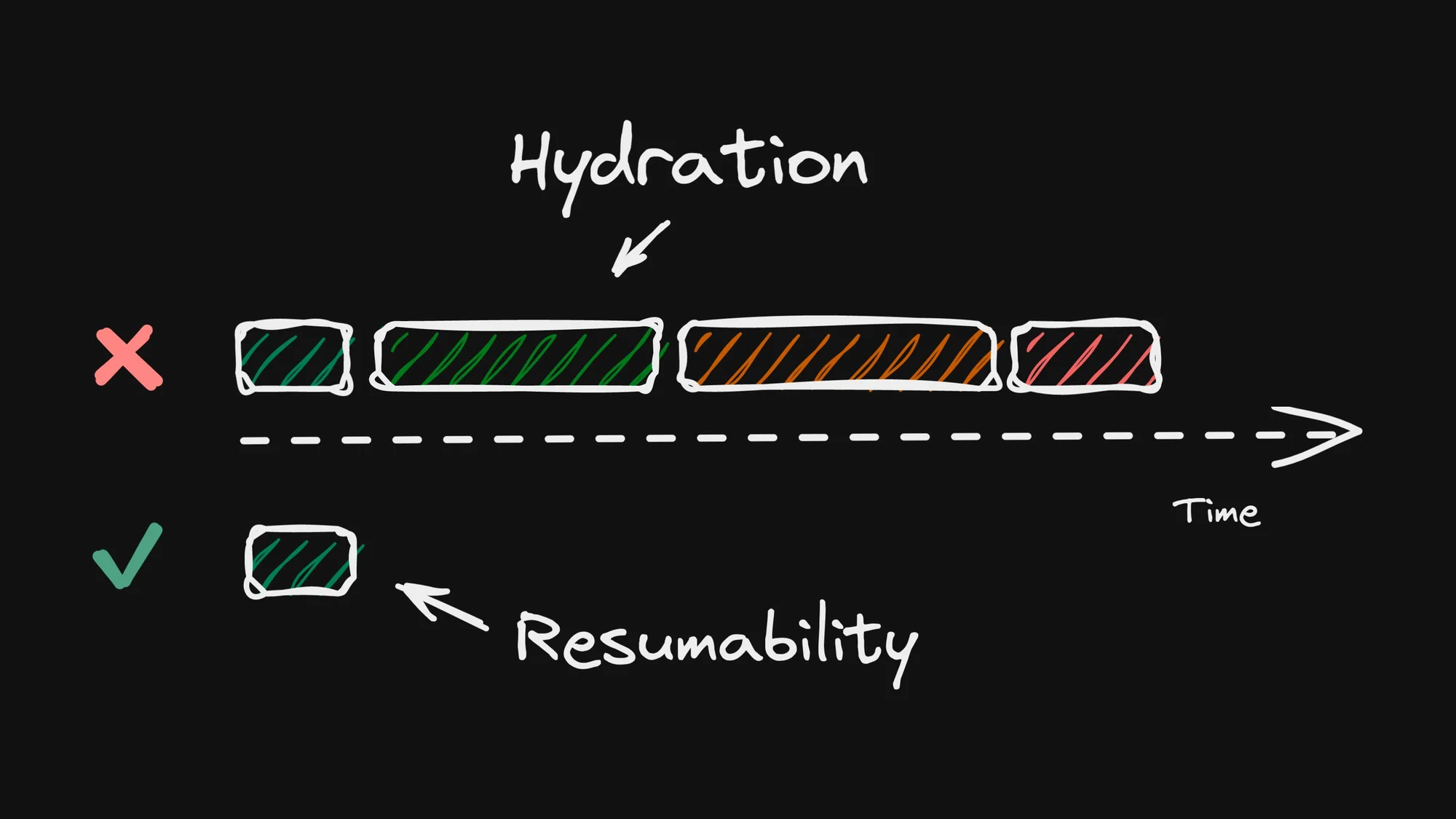
Resumability promises a constant boot time for your application, whereas the current hydration approach has no upper limit on the time it can take. Resumability allows for instant-on applications, and many case studies demonstrate that startup speed impacts your bottom line.
Imagine booting up a virtual machine on your host machine. You watch it go through the boot sequence, login screen, and so on. Then you log in, open a document and start typing a letter. At some point, you save the virtual machine to a file and move the file to a different physical machine.

On the new physical host machine, you open the “saved” virtual machine and it opens to the exact place in the document where you were typing. What you did not have to do was to watch it boot, log in, open the document editor, and enter the document. You resumed where you left off.
Replace “file” with HTML, bootup process with “hydration,” and physical machines with server/client, and you now understand what resumabality is. Resumability is a faster way to get an interactive web application in front of the user by skipping the hydration cost.
Want to know more? Check out these deep dives:
Before we dive into the details, I would like to clarify terminology that is important for the discussion:
- App-code: code that the developer writes to describe the application.
- Framework: a third-party library the developer uses when creating the application.
- Global event handler: a small piece of JS that must eagerly run to set up global event handling.
The key insight is that web applications don’t do anything by themselves. They only perform work due to some external event. (You can think of setInterval IntersectionObserver as a kind of event.)
If we somehow serialize the location of all events in an application during SSR, the client would not need to do anything on startup. The client would just wait for the next event to process. This would make the startup essentially instant, as there is no app-code JavaScript to execute on startup.
How can we serialize the event handlers? Let’s build a pared-down counter application.
function Counter() {
const [count, setCount] = useState(0);
return <button
onClick={() => setCount(count+1)}
>
{count}
</button>;
}As part of the SSR we will generate HTML, which will be like this:
<button>0</button>The problem with the above HTML is that we need to gain information about the fact that the button has a click listener. The standard approach to recover the click listener is to re-run the application (hydration) on the client, but that is precisely what we wish to avoid.
So let’s try to serialize the fact that it has a click listener:
<button on:click="./button-handler.js">0</button>Perfect, we serialized it, but how do we make it work?
The above code will not work because on:click has no particular meaning to the browser. So instead, we need a way to teach the browser what these attributes mean. Enter the global event handler.
The global event handler is a tiny piece of code (about 1kb) that “teaches” the browser how to process the on:click attributes. This piece of code must execute eagerly to enable the behavior.
The global event handler looks something like this (simplified psuedo-code):
allPossibleEventsInApplication.forEach(async (eventName) => {
document.addEventListener(eventName, (event) => {
const url = event.target.getAttribute('on:' + eventName);
if (url) {
(await import(url)).default();
}
});
});The code sets up a global listener for all relevant events and relies on the fact that events bubble up. When the event occurs, the global listener looks for the corresponding on:click attribute, and if found, it uses the attribute as a URL to the code which needs to be loaded.
The important thing to take away is that the global event handler is constant in size. It has nothing to do with your application code, as it is entirely generic.
OK, we now have this HTML, which contains information about the event listeners.
<button on:click="./button-handler.js">0</button>
But we have a problem. Where does button-handler.js come from?
Remember, our application looks like this:
export function Counter() {
const [count, setCount] = useState(0);
return <button
onClick={() => setCount(count+1)}
>
{count}
</button>;
}What we want is to get a hold of this closure: () => setCount(count+1), and as of right now, we can’t do that because it is not a top-level export. The only way we can get a hold of the event handler function is to download the application and execute it to get a hold of the event handler. But that is precisely what makes it hydration and not resumable. Resumable requires that we somehow skip that part.
So we need to have a way to transform the above code to something like this:
export function Counter() {
const [count, setCount] = useState(0);
return <button
onClick="./button-handler.js" // <==== HERE
>
{count}
</button>;
}And then, move the extracted function to a new file called button-handler.js:
export default () => setCount(count +1);NOTE: Ignore the fact that setCount() and count are undefined. We will deal with that later.
What we did with the above transformation created a new entry point. Our original application only had a single entry point Counter. But that is a problem because if you only have a single entry point, the only thing that can happen is that the code starts executing from that single entry point, and the only thing such code can do is run the whole application. The very thing we are trying to avoid with resumability.
Creating new entry points is a crucial concept of resumability. Our application is simple and only has a single click listener, but real-world applications would have hundreds of listeners and, therefore, hundreds of entry points. Each listener is a potential place where the application can start executing and therefore needs a different entry point.
It would be unreasonable to expect that the developer would be forced to break up their code into so many entry points. It would not be a good DX. So what we need is a way to automate this.
We can do this in two parts:
- Create a tool that can automatically extract such code (let’s call it the Optimizer.)
- Create a marker in the code so the Optimizer knows where such transformations are needed. Let’s assume that a marker is
$character at the end of a function name or JSX property.
Tip: This may be an excellent time to read WTF is Code Extraction.
With the above, let’s rewrite our application:
export function Counter() {
const [count, setCount] = useState(0);
return <button
onClick$={() => setCount(count +1)} // <==== HERE
>
{count}
</button>;
}When the optimizer runs, it breaks the application code into two files:
The original file:
export function Counter() {
const [count, setCount] = useState(0);
return <button
onClick$={'./hash-1234.js#s456'} // <==== HERE
>
{count}
</button>;
}And a new file called hash-1234.js:
export const s456 = () => setCount(count +1)Notice we now made it slightly more complicated. The URL now contains #s456, which allows us to place more than one entry point into a single file. This way, we can ensure that we can place related code into a single file and don’t end up with thousands of small files, which would be counterproductive — more on that later.
To have a resumable application, we must continue execution from an event handler. To do so, we need to serialize the event handle into HTML and extract the event handler code into a top-level export and thus create an entry point.
The 🤯 thing for me is that this is as if the addEventListener() was executed on the server but the listener function executes on the client.
But let’s tie up a few loose ends first…
We extracted our click listener to a top-level export like so:
export default () => setCount(count +1);Unfortunately, this will not work! The issue is that this function refers to setCount() and count, which are undefined in this file. The closure state is not persisted. When you load them, they no longer know what count is (or setCount). They forgot. So let’s fix that. Let’s generate this instead:
export function Counter() {
const [count, setCount] = useState(0);
return <button
onClick$={
toURL('./hash-1234.js#s456', [count, setCount]) // <==== HERE
}
>
{count}
</button>;
}And a new file called hash-1234.js:
export const s456 = () => {
const [count, setCount] = useLexicalScope(); // <==== IMPORTANT BIT
return setCount(count +1);
}Notice that the onClick$ handler now “saves” count and setCount, and the extracted function got rewritten to restore count and setCount using the useLexicalScope() function.
So the problem now becomes that the Counter executes on the server. On the server, we have count and setCount values. In contrast, the click handler executes on the client. How do we get count and setCount from the server to the client? Well, we do the same thing we did with events. We serialize them.
So let’s look at how the above changes our generated HTML:
<button on:click="./hash-1234#s456[0,1]">0</button>
<script>/* global event handler*/</script>
<script type="text/json">
[
0, // state of `count` during serialization
'hash-2345.js#s789[...]', // information which will allow us to
// rebuild `setCount` on the client.
]
<script>OK, a few things changed!
First, notice that the on:click URL now contains an extra array [0,1]. This array includes information that useLexicalScope() will use to recover count and setCount explained next. The array is just a collection of pointers to the serialized state of the system, saying which object should be recovered at position 0, position 1, and so on.
Second, we had to insert an extra <script> tag with JSON. The JSON contains the serialized state of the application AS-WELL-AS serialized state of the framework. This is a key difference. Many meta-frameworks serialize the app's state, but I am unaware of any that can serialize the framework's internal state (outside of Qwik).
Serializing the count is easy; it is just a number 0. But serializing setCount is a lot more complicated because setCount is a closure that closes over the framework's internal state.
Serializing a closure is identical to serializing an event handler, which is also a closure. So in our case, hash-2345.js#s789[...] means go import hash-2345.js find the symbol s789, and restore the internal state of that function based on some implementation detail […].
Now the critical thing to understand is that existing frameworks don’t allow you to look into their closures, serialize them, and restore them. They are just not designed for this. So you need a special framework that can do this, such as Qwik.
So what happens on the first click?
<button on:click="./hash-1234#s456[0,1]">0</button>
<script>/* global event handler*/</script>
<script type="text/json">[0,'hash-2345.js#s789[...]']<script>- The browser receives the above HTML and displays it to the user.
- The browser executes the global-event-handler code so it can receive events.
- Service worker — explained later — starts fetching code.
- DONE. So now we wait. There is nothing more to do. This is what makes the startup instant. The amount of code for the browser to execute is constant. It is just the code in the global event listener.
- The user clicks on the button.
- Global event listener receives the click event.
- We import
hash-1234.jsand then locates456. - The browser executes the click event function:
- The
clickevent function has auseLexicalScope()function, which looks at[0,1]of the originalon:clickURL. useLexicalScope()JSON parses the[0,'hash-2345.js#s789[...]']. This tells it that it should return an array where the first argument is0and the second argument is a function that needs to be resolved by loadinghash-2345, reading symbols789, and so on.useLexicalScope()returnscountandsetCount.- Your original code executes
setCount(count + 1).setCountis a trigger for a framework to re-render the associated component.
The above algorithm allows the application to resume where it left off when it was SSR on the server. But SSG works just as well — or even a CDN cache. A single serialization on the server can resume unlimited copies on the client. So while we talk of SSR, it is optional.
The above example is trivial, so it is hard to say if this is actually faster. But real-world applications have hundreds of components and hundreds or even thousands of listeners. That makes a massive difference because the resumability approach remains constant-time. In contrast, hydration is proportional to the complexity of the application. Hydration has no upper bound on how long it can take.
The above example is trivial. But let’s assume a more complex application where we have several components. It is typical for the application's state to migrate toward the root component. It is common for useState() to cause child components to re-render on state change. This means that a state change will cause the system to download and execute most of the application's components, which is a problem.
Resumability is built upon the idea that resuming the application will help avoid the execution of a large portion of the application code base. Thus, we never need to download it. If the first interaction causes a full app download, it is not clear that resumability is a win.
For this reason, resumability needs fine-grain reactivity. Fine-grain reactivity means that a state change will surgically update the DOM instead of doing a large diffing algorithm. The issue is less with the diffing cost than with the fact that coarse grain reactivity needs all related components’ code to be present and executed. Coarse grain-reactive, in effect, undoes all of the hard work that resumability did to avoid executing (and thus downloading) application code.
For resumability to be effective, the framework must be fine-grain reactive. And signals are a natural way to do that. Read useSignal() is the Future of Web Frameworks to understand more.
Builder.io visually edits code, uses your design system, and sends pull requests.
Builder.io visually edits code, uses your design system, and sends pull requests.
 Connect a Repo
Connect a Repo











